
CentOS 8 部署 ELK 日志分析平台
需求
1.开发人员不能登录线上服务器查看日志 2.各个系统都有日志,日志分散难以查找 3.日志数据量大,查找慢,数据不够实时
解决办法:部署 ELK 平台
ELK 介绍
ELK 是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个 FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash 。
ELK 架构图
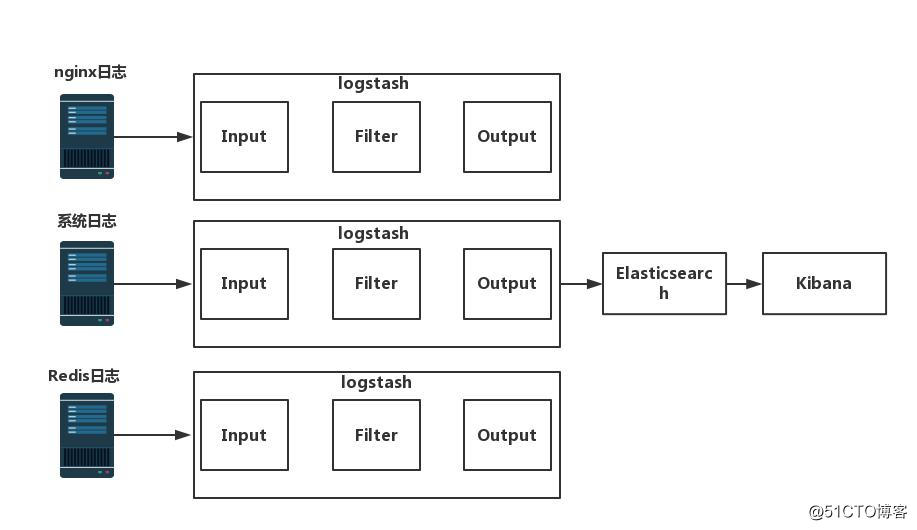
Elasticsearch 简介:
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。 特点:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
部署 Elasticsearch
1.安装 elasticsearch
yum install elasticsearch -y #安装elasticsearch
3. 配置 Elasticsearch
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: yltx #17行 集群名称
node.name: node1 #23行 节点名称
pache.data: /data/es-data #33行工作目录
path.logs: /var/log/elasticsearch #37行日志目录
bootstrap.memory_lock: true #43行 防止交换swap分区
network.host: 0.0.0.0 #54行 监听网络
http.port: 9200 #58行 端口
cluster.initial_master_nodes: ["node-1"] #72行 node
mkdir -p /data/es-data
chown -R elasticsearch:elasticsearch /data/es-data/
4.内存解锁和文件限制
生产环境中必须要修改(注意)
#centos 7
vim /etc/security/limits.conf
末尾插入
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
* soft nofile 65535
* hard nofile 65535
#1) /etc/sysconfig/elasticsearch
vim /etc/sysconfig/elasticsearch
ES_JAVA_OPTS="-Xms4g -Xmx4g"
MAX_LOCKED_MEMORY=unlimited
#(replace 4g with HALF your available RAM as recommended here)
vim /etc/security/limits.conf
#2) On security limits config:
vim /etc/security/limits.conf
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
#3) /usr/lib/systemd/system/elasticsearch.service
vim /usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity
you should do systemctl daemon-reload after changing the service script
vim /etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: true

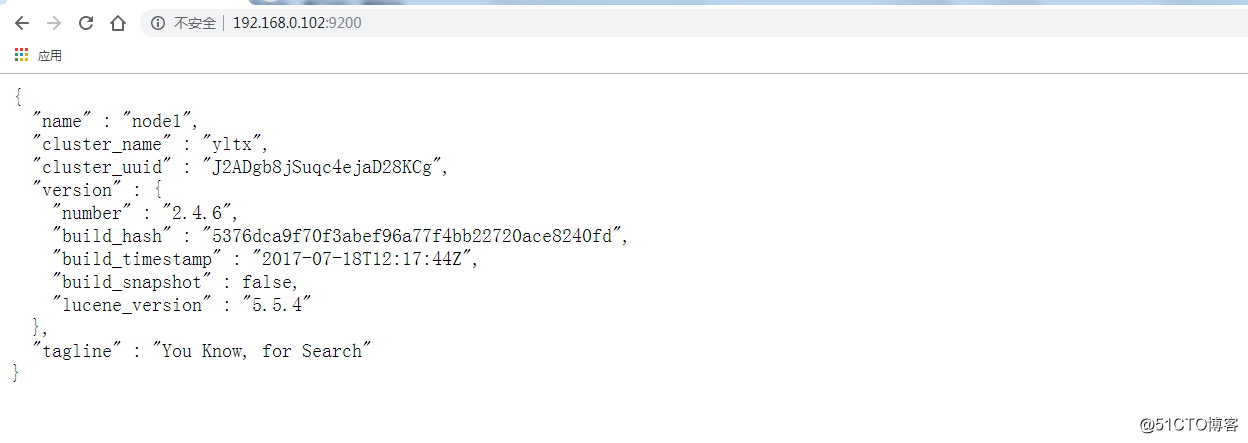
网页测试:http://192.168.0.102:9200/
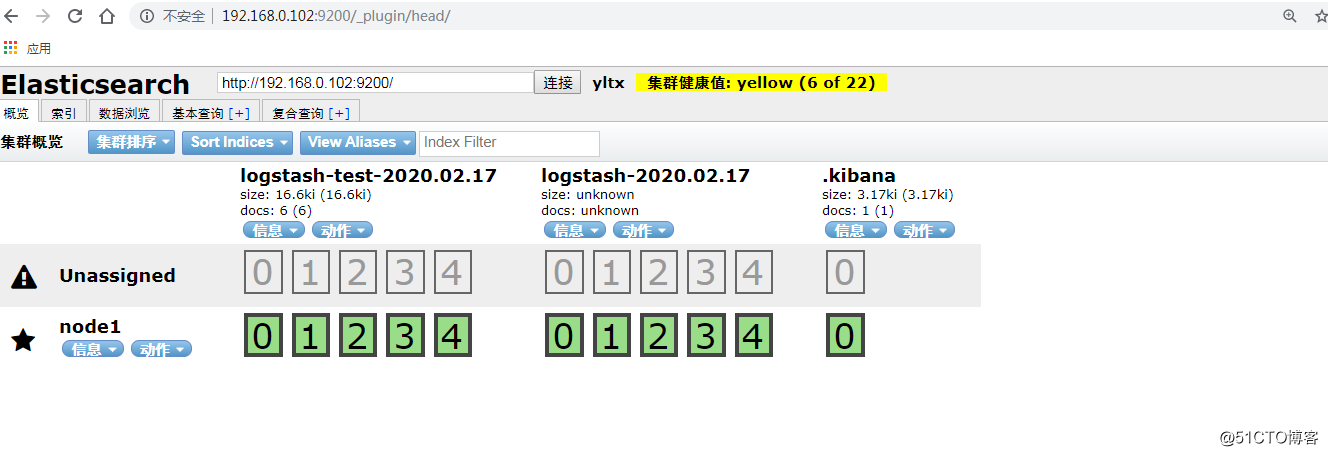
安装 Elasticsearch – head 插件
/usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head

网页访问:
http://192.168.0.102:9200/_plugin/head/
Logstash 介绍:
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch 上去。 logstash 收集日志基本流程: input–>codec–>filter–>codec–>output 1.input:从哪里收集日志。 2.filter:发出去前进行过滤 3.output:输出至 Elasticsearch 或 Redis 消息队列 4.codec:输出至前台,方便边实践边测试 5.数据量不大日志按照月来进行收集
部署 Logstash
1.配置 yum 源
vim /etc/yum.repos.d/logstash.repo
[logstash-2.1]
name=Logstash repository for 2.1.x packages
baseurl=http://packages.elastic.co/logstash/2.1/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enable=1
2.下载安装 logstash
yum install logstash -y
测试 logstash
logstash 的基本语法
input {
指定输入
}
output {
指定输出
}
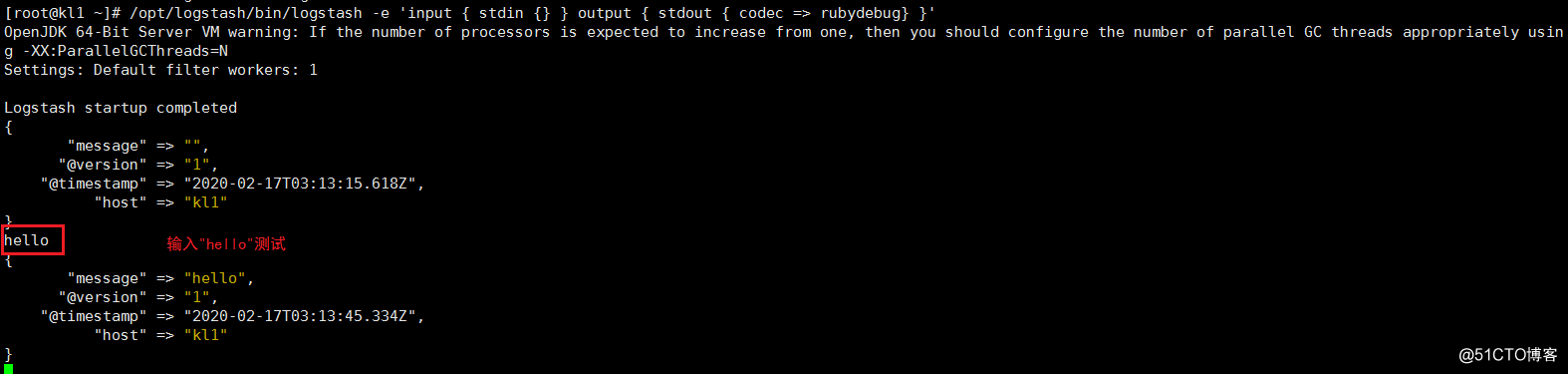
1.测试标准输入输出
#使用rubydebug方式前台输出展示以及测试
/opt/logstash/bin/logstash -e 'input { stdin {} } output { stdout { codec => rubydebug} }'
hello #输入hello测试
2.测试输出到文件
/opt/logstash/bin/logstash -e 'input { stdin {} } output { file { path => "/tmp/test-%{+YYYY.MM.dd}.log"} }'
cat /tmp/test-2020.02.17.log
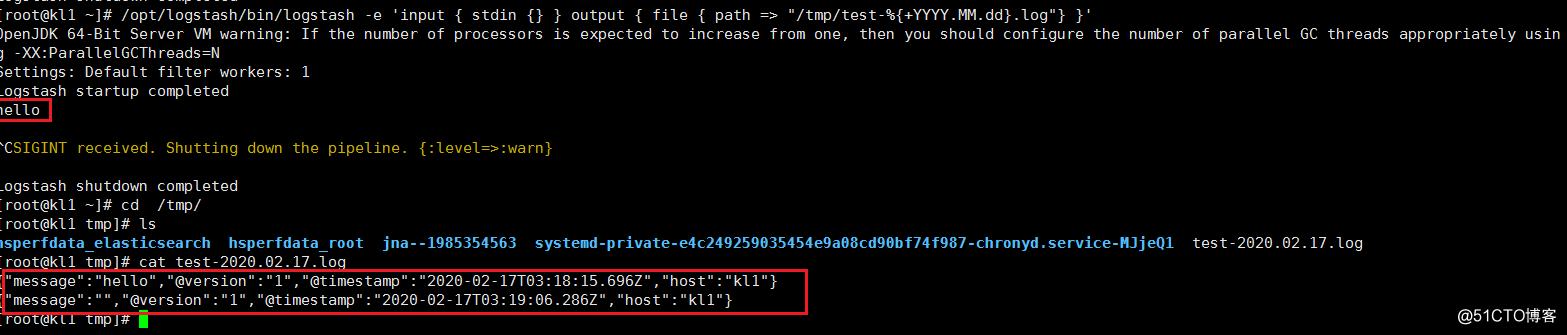
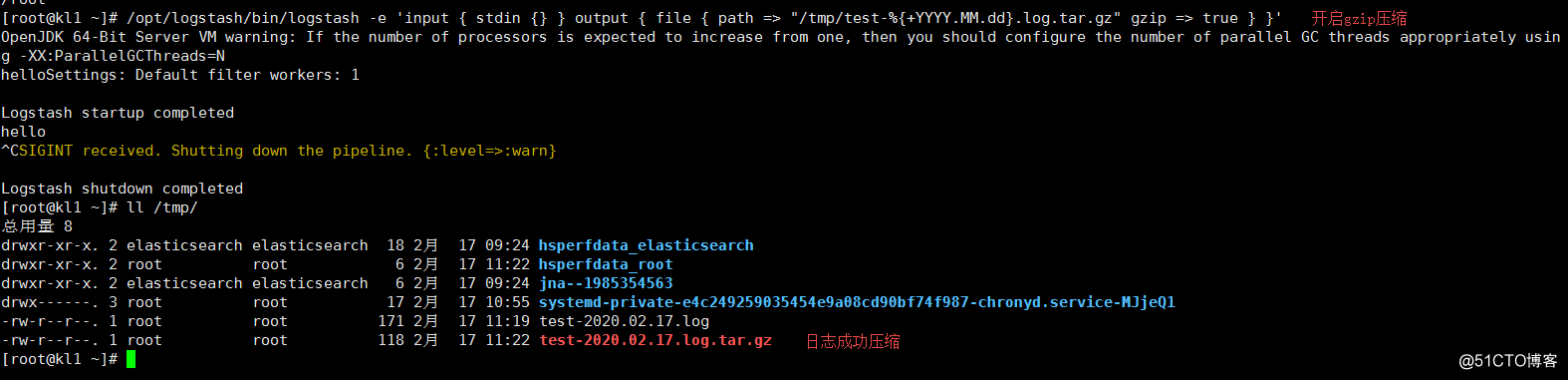
3.开启日志压缩
/opt/logstash/bin/logstash -e 'input { stdin {} } output { file { path => "/tmp/test-%{+YYYY.MM.dd}.log.tar.gz" gzip => true } }'
ll /tmp/
4.测试输出到 elasticsearch
/usr/share/logstash/bin/logstash -e
'input { stdin {} } output { elasticsearch { hosts => ["localhost:9200"] index => "logstash-test-%{+YYYY.MM.dd}" } }'
ll /data/es-data/yltx/nodes/0/indices
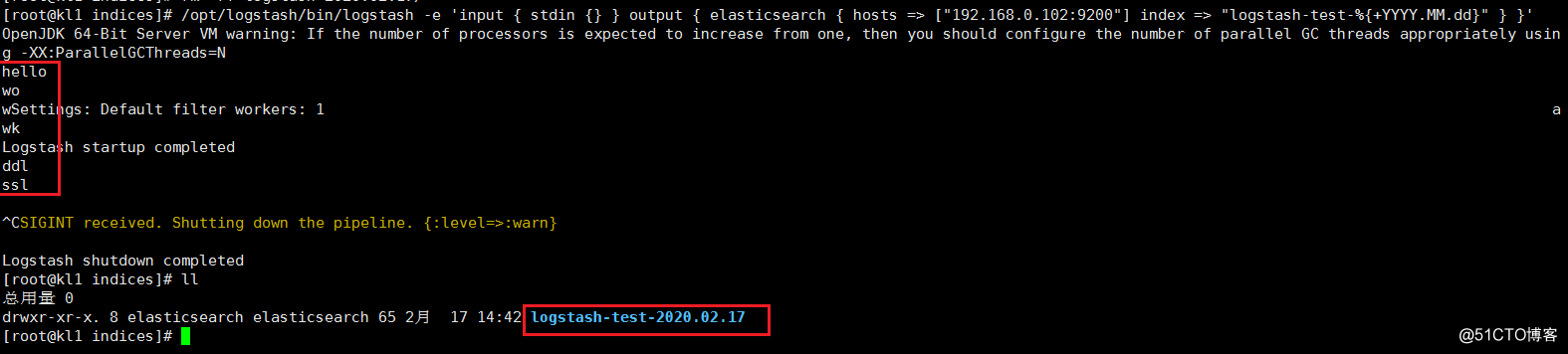

5.网页验证
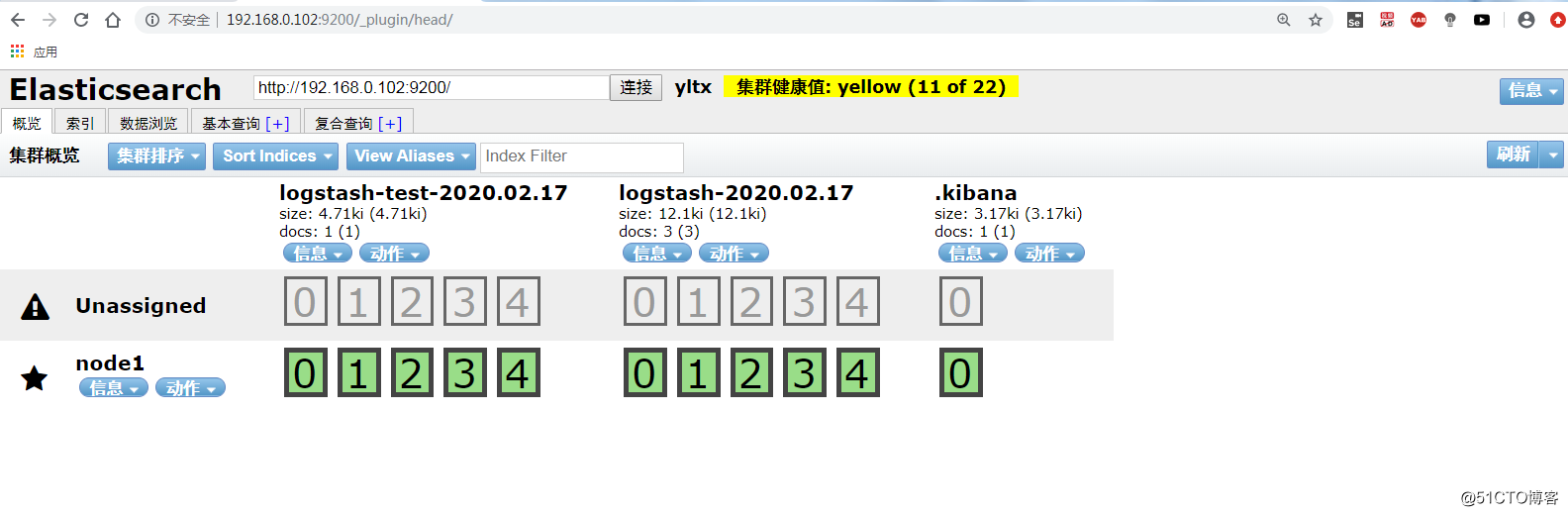
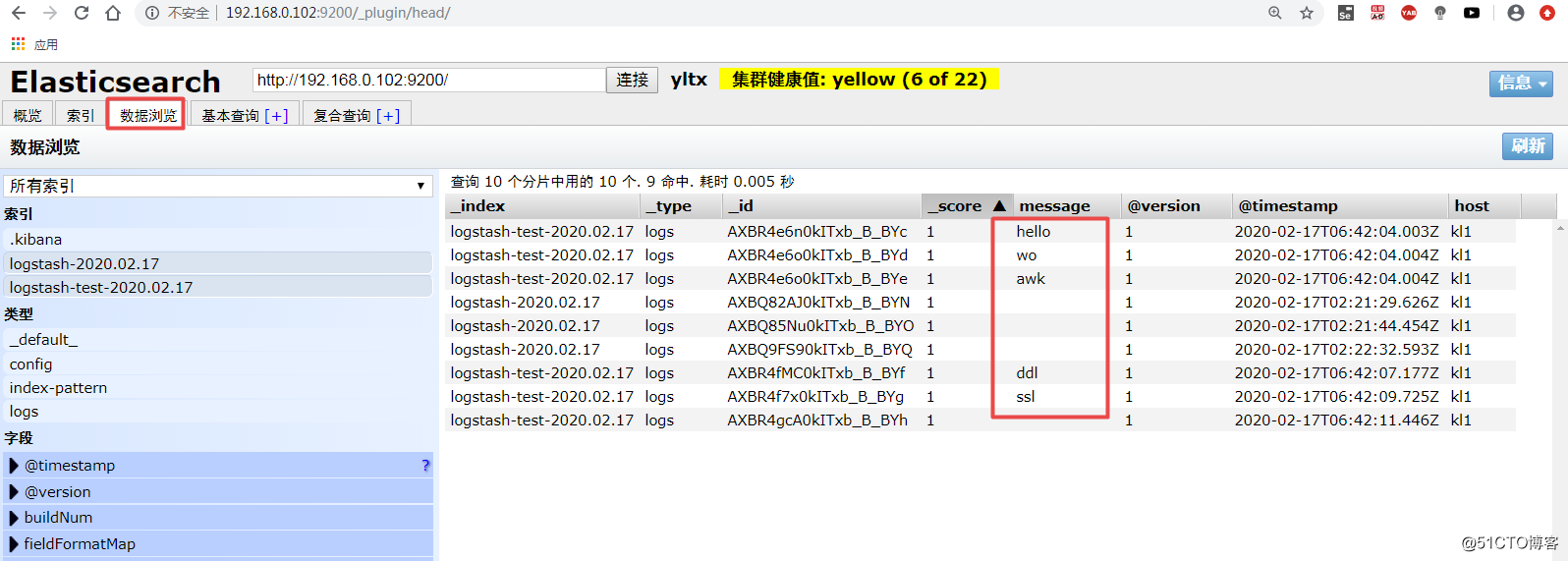
Kibana 简介
Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Kibana 部署
1.下载安装 kibana
wget https://repo.huaweicloud.com/kibana/7.8.0/kibana-7.8.0-x86_64.rpm
yum install kibana-7.8.0-x86_64.rpm
2.修改配置
vim /etc/kibana/kibana.yml
server.port: 5601 #2行 访问端口
server.host: "0.0.0.0" #5行 监听网络
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana" #20行
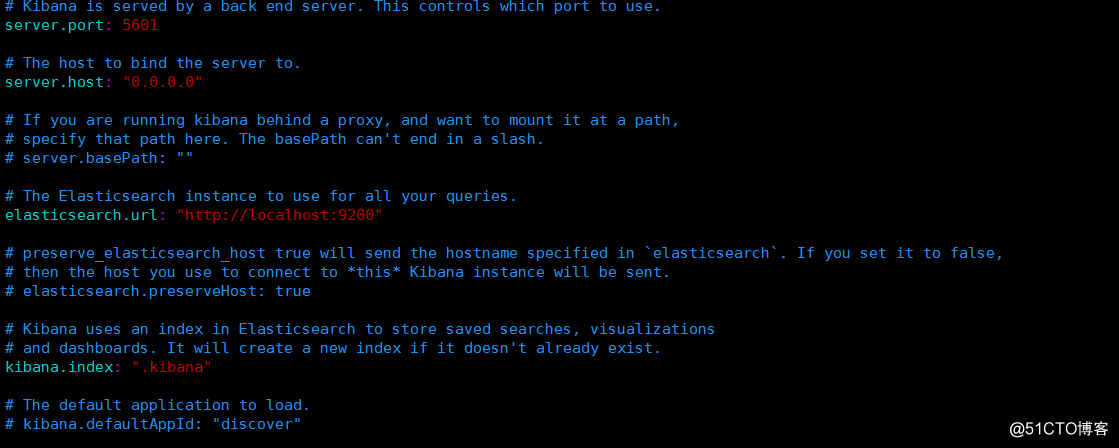
3.启动服务
systemctl enable kibana

4.网页验证:
http://192.168.0.102:5601/
测试 ELK 平台
收集系统日志和收集 java 异常日志
1.修改 nginx 配置文件:
vim /usr/local/nginx/conf/nginx.cof
access_log /var/logs/nginx/access.log;
error_log /var/logs/nginx/error.log error;
2.写入到 elasticsearch 中
sudo vi /etc/logstash/conf.d/02-nginx-input.conf
input {
file {
path => ["/var/log/nginx/access.log", "/var/log/nginx/error.log"]
type => "nginx"
}
}
sudo vi /etc/logstash/conf.d/10-nginx-filter.conf
filter {
grok {
match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"]
overwrite => [ "message" ]
}
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
geoip {
source => "clientip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field => [ "timestamp" ]
}
useragent {
source => "agent"
}
}
sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-%{+YYYY.MM.dd}"
document_type => "nginx_logs"
}
stdout { codec => rubydebug }
}
###
3.查看 Elasticsearch
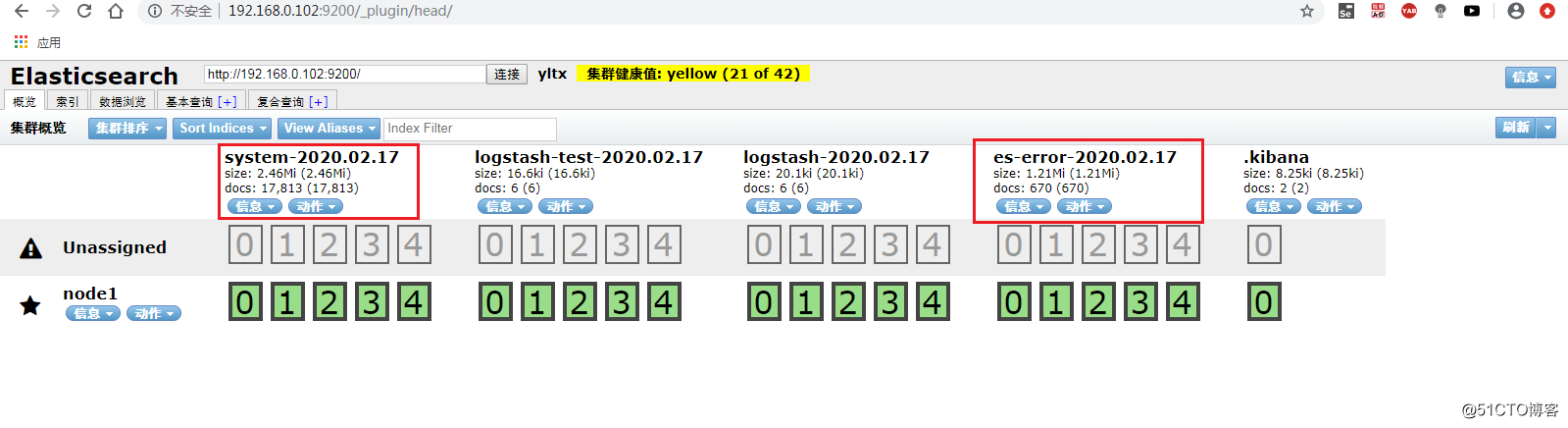
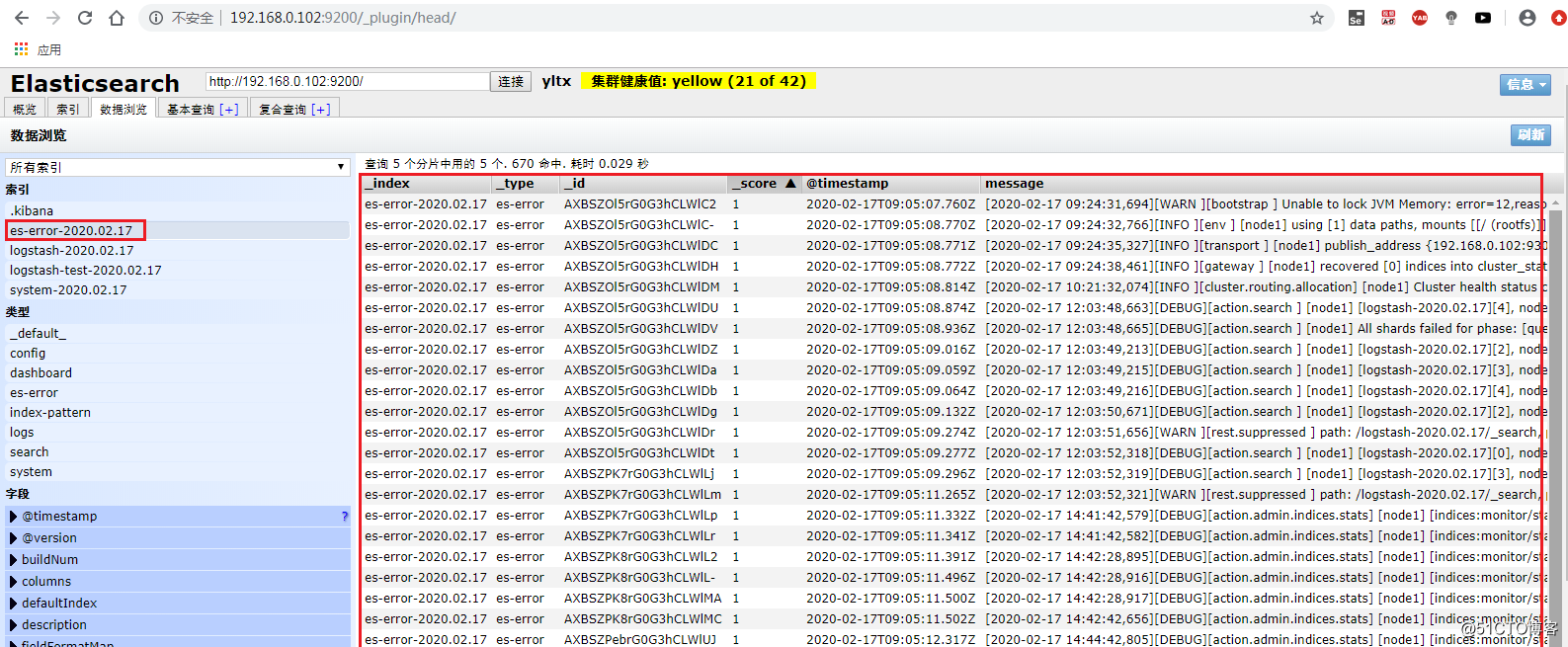
4.查看 Kibana
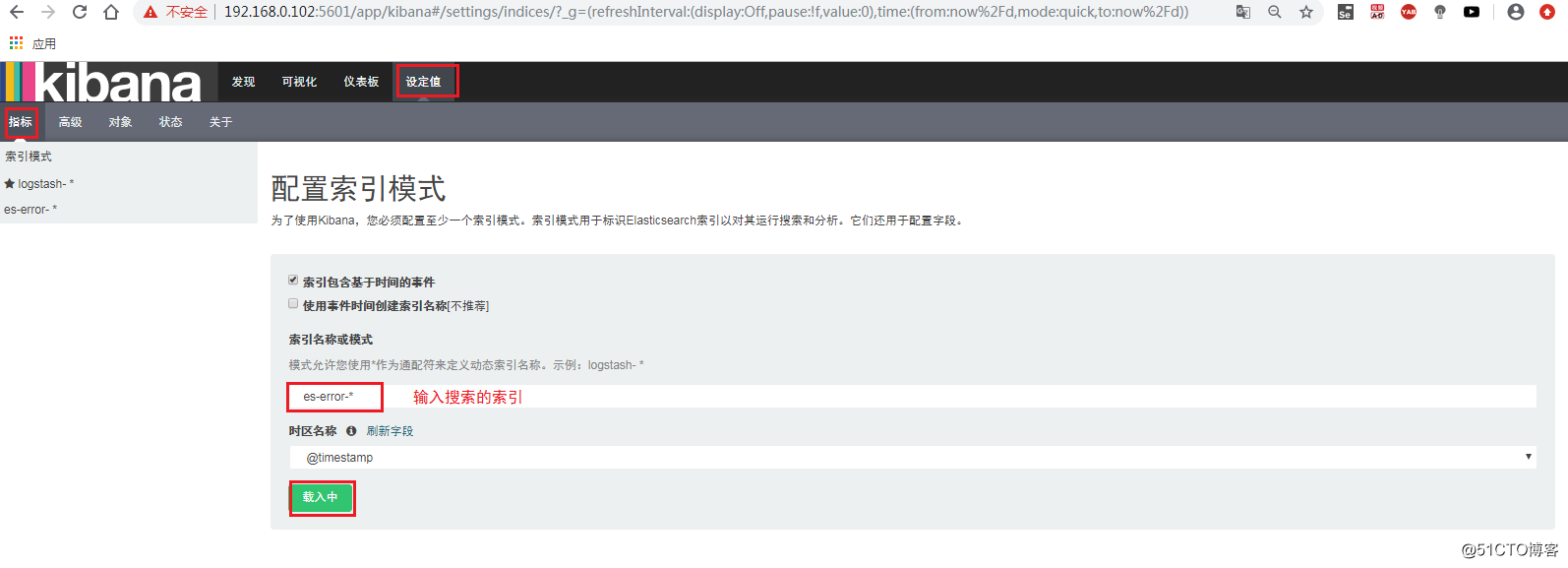
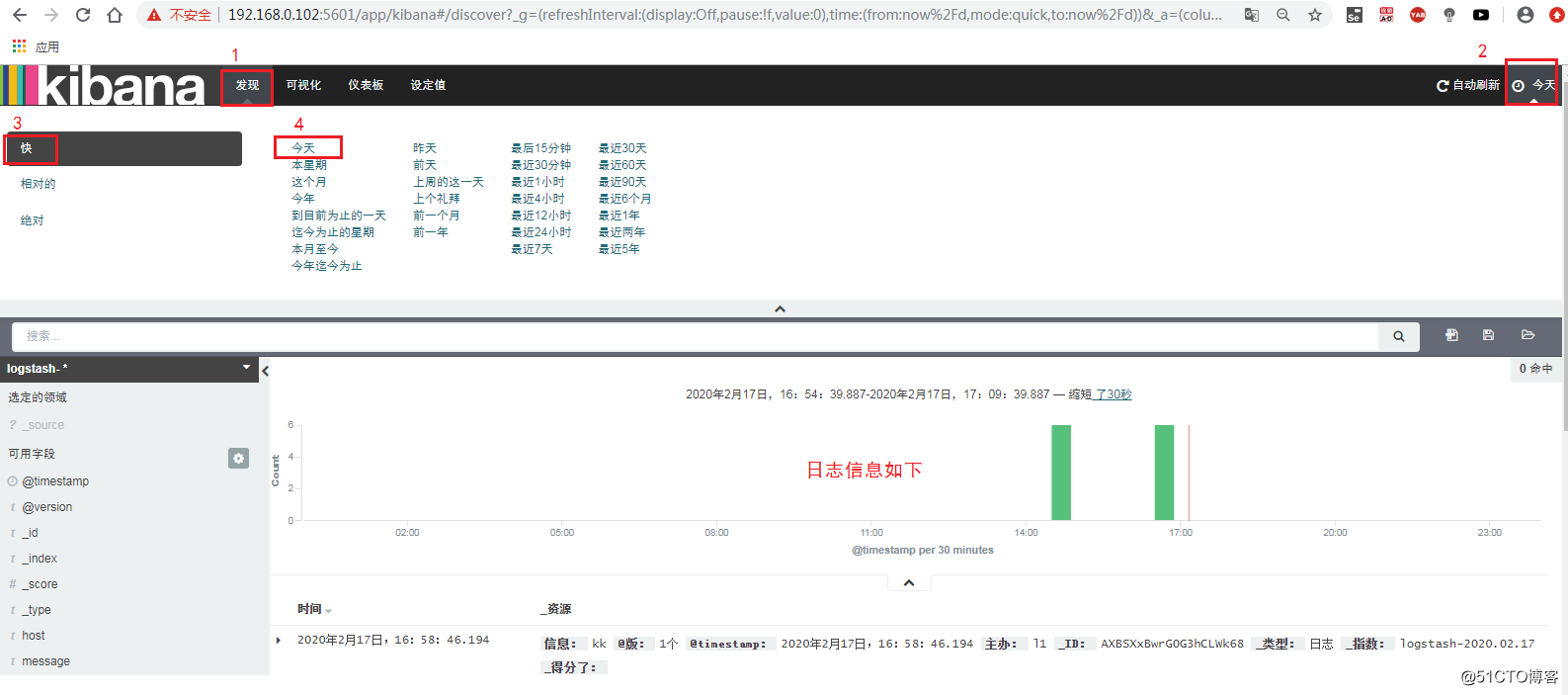
安装 Filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
sudo rpm -vi filebeat-7.3.1-x86_64.rpm
使用 Filebeat 模块
当我们安装完 Filebeat 后,我们可以看到在 Filebeat 的安装目录下的文件结果如下:
$ pwd
/Users/liuxg/elastic/filebeat-7.3.0-darwin-x86_64
(base) localhost:filebeat-7.3.0-darwin-x86_64 liuxg$ ls -F
LICENSE.txt filebeat.reference.yml filebeat_es.yml
NOTICE.txt filebeat.template.json kibana/
README.md filebeat.yml logs/
data/ filebeat1.yml module/
fields.yml filebeat2.yml modules.d/
filebeat* filebeat_apache.yml sample.log
在这里,我们可以看到它里面有一个叫做 filebeat.yml 的配置文件,还有一个叫做 modules.d 的文件夹。在 filebeat.yml 中,我们做如下的修改:
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
fields_under_root: true
fields:
host: ${serverIP}
在这里,我们把 host 都指向我们的 localhost,这是因为我们的 elasticsearch 及 Kibana 都安装在本地的电脑上。这两个地址需要根据自己实际的部署的地址改变而改变。
显示 Filebeat 支持的模块
$ ./filebeat modules list
Enabled:
nginx
Disabled:
apache
auditd
cisco
coredns
elasticsearch
envoyproxy
googlecloud
haproxy
icinga
iis
iptables
kafka
kibana
logstash
mongodb
mssql
mysql
nats
netflow
osquery
panw
postgresql
rabbitmq
redis
santa
suricata
system
traefik
zeek
我们可以看出来目前已经被启动的模块是 nginx。它可以通过如下方式来启动:
./filebeat modules enable nginx
当然我们也可以通过如下的方式来关闭这个模块:
./filebeat modules disable nginx
针对我们今天的练习,我们需要启动 nginx 模块。
我们可以通过如下的命令查看在 modules.d 目录下的文件变化:
$ pwd
/Users/liuxg/elastic/filebeat-7.3.0-darwin-x86_64
(base) localhost:filebeat-7.3.0-darwin-x86_64 liuxg$ ls modules.d
apache.yml.disabled mssql.yml.disabled
auditd.yml.disabled mysql.yml.disabled
cisco.yml.disabled nats.yml.disabled
coredns.yml.disabled netflow.yml.disabled
elasticsearch.yml.disabled nginx.yml
envoyproxy.yml.disabled osquery.yml.disabled
googlecloud.yml.disabled panw.yml.disabled
haproxy.yml.disabled postgresql.yml.disabled
icinga.yml.disabled rabbitmq.yml.disabled
iis.yml.disabled redis.yml.disabled
iptables.yml.disabled santa.yml.disabled
kafka.yml.disabled suricata.yml.disabled
kibana.yml.disabled system.yml.disabled
logstash.yml.disabled traefik.yml.disabled
mongodb.yml.disabled zeek.yml.disabled
我们可以看到 nginx.yml 文件的最后没有 “disabled” 字样,表明它已经被启动成功。我们进一步编辑这个 nginx.yml 文件:
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.3/filebeat-module-nginx.html
- module: nginx
# Access logs
access:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/Users/liuxg/data/nginx.log"]
# Error logs
error:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: ["/var/log/nginx/error.log"]
在这里,我把文件路径 /Users/liuxg/data/nginx.log 写入到该文件,这是因为我的 nginx.log 文件是位于这个路径的。这个路径需要你依据把 nginx 的日志文件路径改变而改变。
启动模块
为了能够使得我们的 nginx 模块能够正确地被 Kibana 显示,我们必须运行如下的命令:
$ pwd
/Users/liuxg/elastic/filebeat-7.3.0-darwin-x86_64
(base) localhost:filebeat-7.3.0-darwin-x86_64 liuxg$ ./filebeat setup
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Loaded machine learning job configurations
Loaded Ingest pipelines
注意:在安装或升级 Filebeat 时,或在启用新模块后,必须执行 setup 命令
运行 Filebeat
上面我们已经配置好,下面我们通过如下的命令来把我们的 nginx 日志导入到我们的 Elasticsearch 中:
./filebeat -e

我们可以在 Kibana 的 “Dev tools” 可以看到最新被创建的 index:

这里的 filebeat-7.3.0 是一个 alias,它指向我们刚被创建的一个 index,比如 filebeat-7.3.0-2019.09.28-000001。
在这里显示的数据是 10,000,其实这不是一个真实的文档的数目。它的真实的文档个数是:

这里要注意的一件事是响应中的 hits.total。 它具有 10,000 和 “relation” =“ gte” 的值。 索引中实际上有 984,887 个文档,我们已经创建了全部。 在 7.0 版发布之前,hits.total 始终用于表示符合查询条件的文档的实际数量。 在 Elasticsearch 7.0 版中,如果匹配数大于 10,000,则不会计算 hits.total。 这是为了避免为给定查询计算精确匹配文档的不必要开销。 我们可以通过将 track_total_hits = true 作为请求参数来强制进行精确匹配的计算。
一旦数据被导入到 Elasticsearch 中,我们就可以开始对数据进行分析了。
运用 Kibana 来分析数据
在之前我们已经通过 ./filebeat setup 命令,已经把针对 nginx 的模块仪表盘导入到 Kibana 中了。下面我们就可以使用标准的 dashboard 来对 nginx 数据进行展示及分析。
打开 Discover 查看数据,index pattern 选择 filebeat-*,把时间选择到 2018 年 10 月-2018 年 12 月停止

